Abstract
Modern image super-resolution techniques generally use multiple losses when training. Many techniques use a GAN loss to aid in producing high-frequency details. This GAN loss comes at a cost of producing high-frequency artifacts and distortions on the source image. In this post, I propose a simple regularization method for reducing those artifacts in any SRGAN model.
Background on SR Losses
Most SR models use composite losses to achieve realistic outputs. A pixel-wise loss and/or a perceptual loss coerces the generator to produce images that look structurally similar to the input low-resolution image. With only these losses, the network converges on producing high-resolution images that are essentially the numerical mean of all of the training data.
To humans, this results in an output image that is blurred and overly smoothed. High-frequency details like pock-marks, individual hair strands, fine scratches, etc are not represented in the high-resolution images. These can be appealing to the eye, but they are also clearly artificial.
To improve on this situation, adding a GAN loss was proposed in the SRGAN paper from 2017. This loss is effective in bringing back many high-frequency details, but comes at a cost: the generator eventually begins to learn to “trick” the discriminator by adding high-frequency artifacts in the image.

These artifacts range from mild to extremely bothersome. I have observed them simply removing eyebrows from faces to distorting hands or feet into giant blobs, even when the structural information for those feature were in the low-resolution images. Images generated from GAN SR networks are therefore generally more realistic than their perceptual counterparts, but are even more unsuited for general use since their failure mode is so severe.
Existing Solutions to SRGAN Artifacts
There are many proposed solutions to GAN artifacts. To name a few:
SPSR trains two separate networks: one built on top of images that have been fed through an edge detector and one on the raw image. The logic is that the network is induced to preserve the structure of the low-resolution image throughout the upsampling process.
TecoGAN (and other video SR architectures) improve the state by adding temporal coherence losses, which forces the generator to be self-consistent across multiple frames.
GLEAN uses a pretrained generative network trained with only a GAN loss to guide the SRGAN process towards realistic high-frequency textures.
Approaching the problem by posing the loss in the frequency-domain or after a wavelet transform have also been explored as solutions to the problem.
Of these, I have found that the TecoGAN approach leads to the most impressive reduction in GAN artifacts. It is particularly intriguing because even though the intention of the paper was to improve temporal consistency, the authors also achieved superior single-image super-resolution.
Exploring Self Consistency Losses
The main divergence between SRGAN and TecoGAN is the pingpong loss proposed the TecoGAN paper. This loss is derived by feeding a series of warped video frames recursively forward then backward through the generative network. The same high-resolution video frame before and after this recursive feedforward is compared to each other with a simple pixel loss. The idea is that artifacts introduced by the network will necessarily grow during the “ping-pong” process causing inconsistent outputs which could then be trained away.
This type of self-consistency loss is more powerful than the standard L1/L2 loss against a fixed target because the network can learn to be self-consistent from the gradients of the feedforward passes that produced both the images. For example, the network can learn to fix the problem of growing artifacts by suppressing those artifacts early on (in the first pass of the network) or suppressing their growth by accumulating a better statistical understanding of the underlying natural image. Either way, downstream quality is a result.
Self Consistency Losses for Single Image Super Resolution
The same recursive redundancy loss can be performed for single images as well. The basic method to do this is to take an HQ image and derive two LQ images that share some region from that HQ image. Then, feed these LQ images through your generator and compare the same regions in the generated results.
There are actually many ways you can do this. Basically any image augmentation you might read from DiffAug or such works. For the purposes of image SR, you should probably steer away from color shifts or blurs, but translation, rotation and zooms are great methods.
Having tried all three, I have had particular success with translation. The following simple algorithm has had a noticeable effect on image quality for all of my SR networks:

- For any given HQ image, crop LQ patches from each corner of the image. For example, from a 256px image, extract 4 224px patches.
- Randomly pick any single corner image to feed forward through the network for the normal losses (e.g. L1, perceptual, GAN).
- Pull the region from (2) that is shared with all corner crops.
- Randomly pick a second corner crop, feed it forward, and crop out the region of the image that is shared with all corner crops.
- Perform an L1 loss between the results from (4) and (3).
This algorithm can be further improved upon by selecting crops that don’t necessarily need to start in the image corners, but I am not sure that the additional complexity warrants improvements. Sheer and zoom can also be added, but this also adds complexity (particularly regarding pixel alignment). I have tried zoom losses and they did not add significant performance gains.
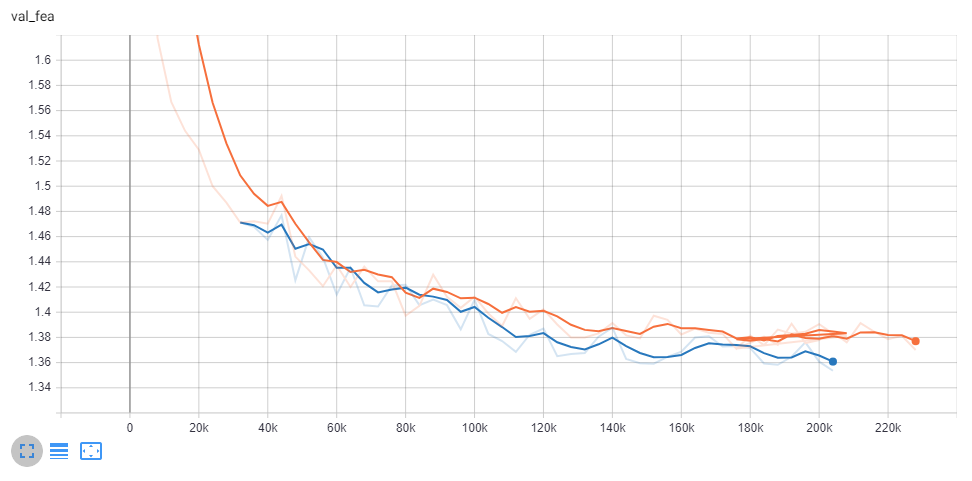
One note about this loss: it should not be applied to an SR network until after it begins to produce coherent images. Applying the loss from the start of training results in networks that never converge because their initial outputs are so noisy that the translational loss dominates the landscape. The TecoGAN authors noted the same result with their ping-pong loss, as an example.