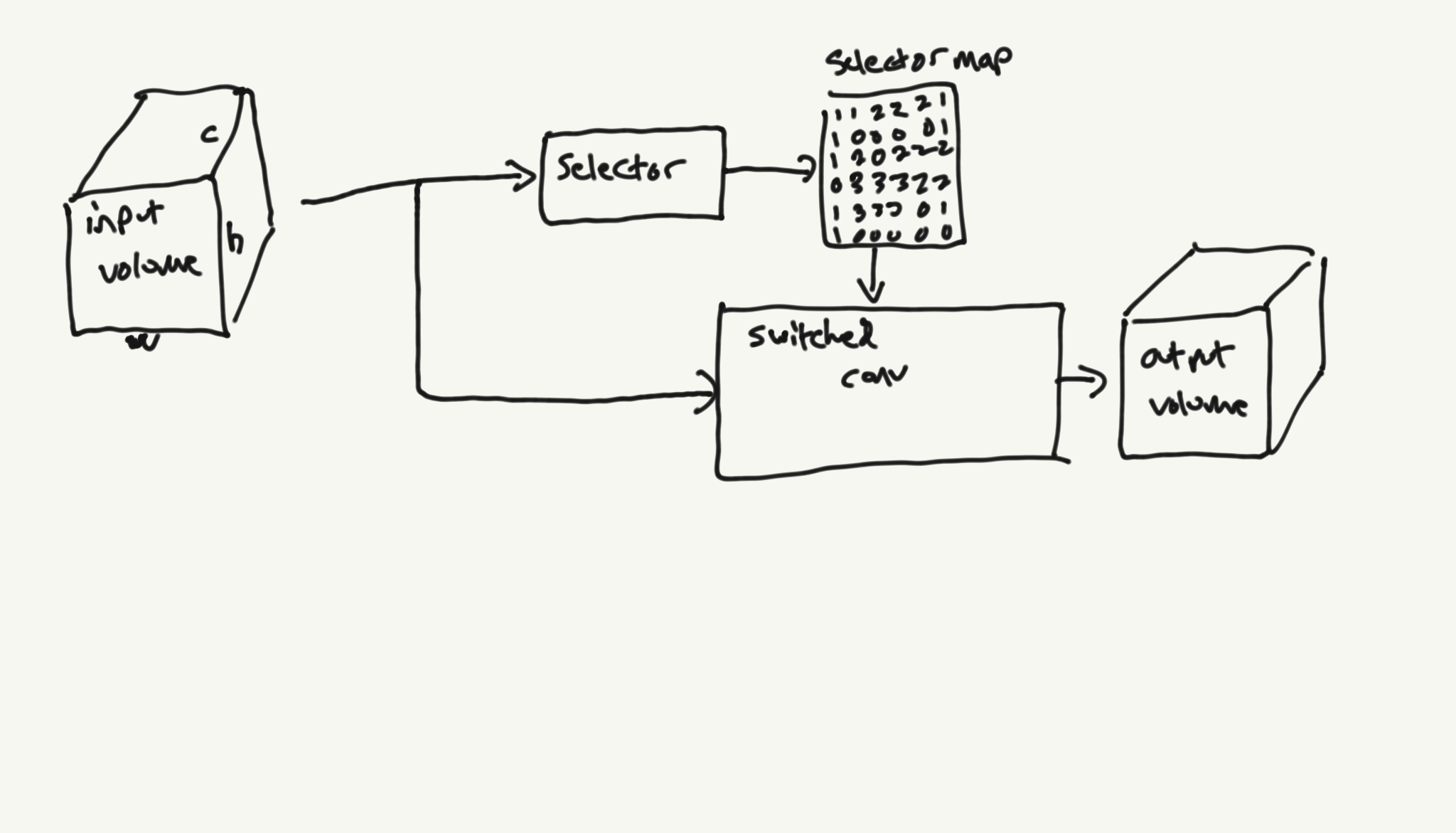
Switched Convolutions – Spatial MoE for Convolutions Abstract I present switched convolutions: a method for scaling the parameter count of convolutions by learning a mapping across the spatial dimension that selects the convolutional kernel to be used at each location. I show how this method can be implemented in a way that has only a…