Lab notes is a way for me to openly blog about the things I am building. I intend to talk about things I am building and the methods I plan to use to build them. Everything written here should be treated with a healthy amount of skepticism.
I’ve been researching something this week that shows a lot of promise, and I really wanted to write about it. I call them “cheater latents”. They’re inspired by something I observed from Tortoise: in an early version of Tortoise, I trained the AR model by using the output clip itself as the conditioning input. What that looked like is this:
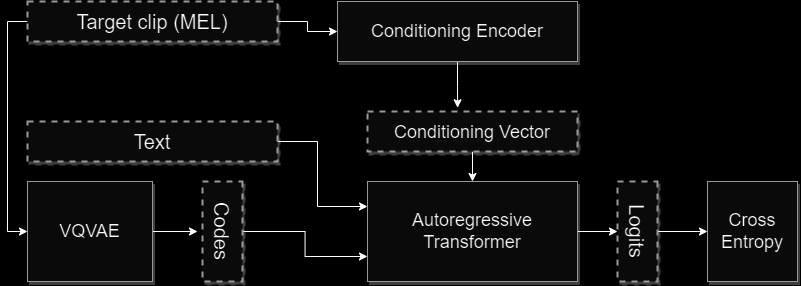
I was surprised by how well this worked in validation, but then quickly grew dismayed when I noticed that it had very poor generalization performance. It would only work great when the text spoken in the conditioning clip was exactly the text provided to the model to render.
This drew me to an amusing conclusion: the AR model was learning how to compress every aspect of speech (down to the words spoken) into the conditioning vector. This was actually good news for Tortoise: the learned conditioning vector ploy I was using could work. It also showed how good AR decoders are at “cheating”: give them a little bit too much information about the target space, and they’ll learn how to cheat at your problem.
Fast forward, and I am trying to find ways to highly compress music. I want to produce coherent, ~3 minute clips. This is way too long of a sequence length for full attention, even if the clips are converted to a spectral representation (as has been my plan). After chipping away at the problem in my head for several weeks, occurred to me that my Tortoise-training experience outlined above might be relevant for this problem. Here’s what I built to test this out:
- Train a VQVAE to convert music spectrograms into discrete codes. (*)
- Train a network that convert binned, magnitude-only spectrograms back into waveforms (a vocoder, for music) (*)
- Train an AR decoder that does next-sequence-prediction, conditioned on the output of a “cheater encoder” which compresses the target spectrogram.
- Throw out the AR decoder, keep the cheater encoder.
- Train a diffusion model which reconstructs the target spectrogram given the outputs of the cheater encoder from (3).
* I have had these networks built for some time now. Nothing to see here. 🙂
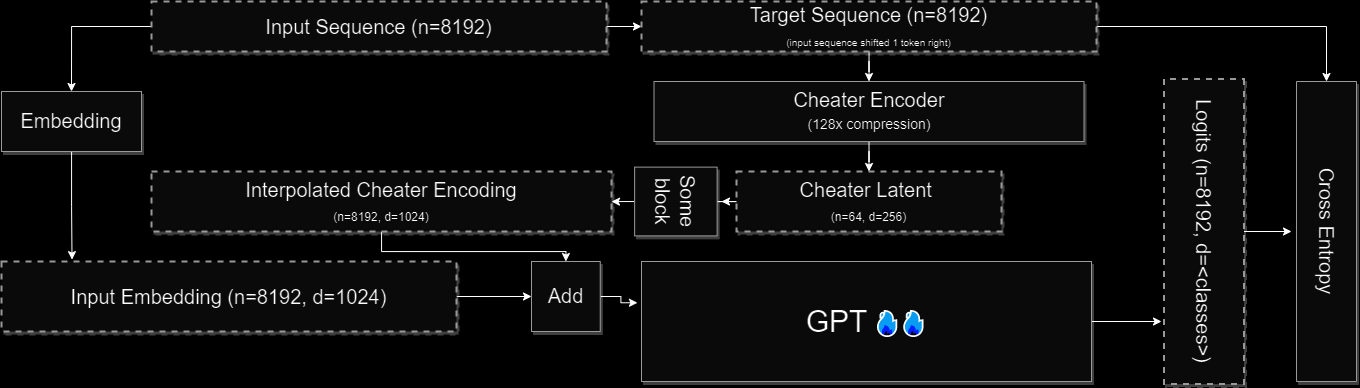
This works. Well. Much better than a diffusion network trained on the VQVAE codes, despite the fact that the encoder representation has 16x more spatial compression than the codes. I call these encoder representations “cheater latents” because of how they are trained – inducing a NN to do what it does best: cheat. Note that while the conditioning vector from the first diagram is a “cheater latent”, I think the more interesting form of these latents is when they form a compressed sequence of latent vectors:
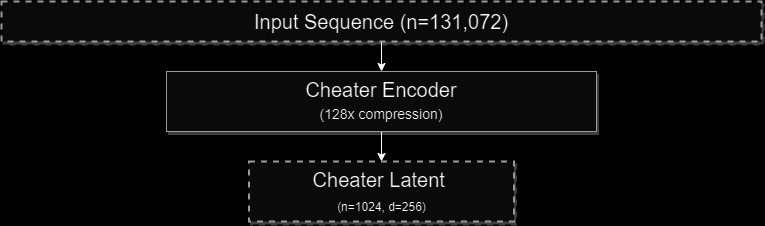
This is still hot off the presses and I have a lot more playing to do, but I am really excited about furthering this line of research. It is (potentially) a completely unsupervised method of learning robust compressed vector representations of any input space. Here are the two big use-cases I really want to explore:
- Generation: With the advent of diffusion models, we now have the tools to generate entire latent spaces. It should therefore be feasible to model these cheater latents with a diffusion model. Such a model would be performing diffusion in a highly compact space. It would be possible to train such a model on a 3 minute (or 10 minute! or 1 hour!) audio clip. This efficiency means we could scale the parameters of the model much more easily – which is the true goal.
- Memory: I believe these representations could be used as a simple solution to memory in LLMs. Here is the scheme:
- Learn cheater latents by training a classical GPT which is conditioned on a highly compressed encoding of the target text.
- Train a GPT-style LLM where only the most recent <N> inputs are traditional token embeddings. The LLM also receives a large context consisting of cheater latents derived from a much larger input corpus.
- During inference, every few AR steps, you “compact” the context into a cheater latent. This would allow an enormous (expressive!) input context.
If anyone is interested in playing with this concept, please reach out. I’d be happy to share the code and techniques.