Batch size is one of the oldest hyper parameters in SGD, but it doesn’t get enough attention for super-resolution GANs.
The problem starts with the fact that most SR algorithms are notorious GPU memory hogs. This is because they generally operate on high-dimensional images at high convolutional filter counts.
To put this in context, the final intermediate tensor of the classic RRDB model has a shape of (<bs>x64x128x128) or over 33M floats at a batch size of 32. This one tensor consumes more than 10% of the models total memory usage!
To cope with this high memory usage, SR papers often recommend training with miniscule batch sizes in the regime of 4-16 samples per batch. This is wholly inadequate, as I will discuss in this article.
Larger batches are (almost) always better
Training SR models with larger batch sizes results in an immediate permanent improvement in performance of every SR model I have trained thus far. I discovered this on a whim with a custom model I was developing, but found out later that it applies to RRDB and SRResNet as well. Here is an example plot:
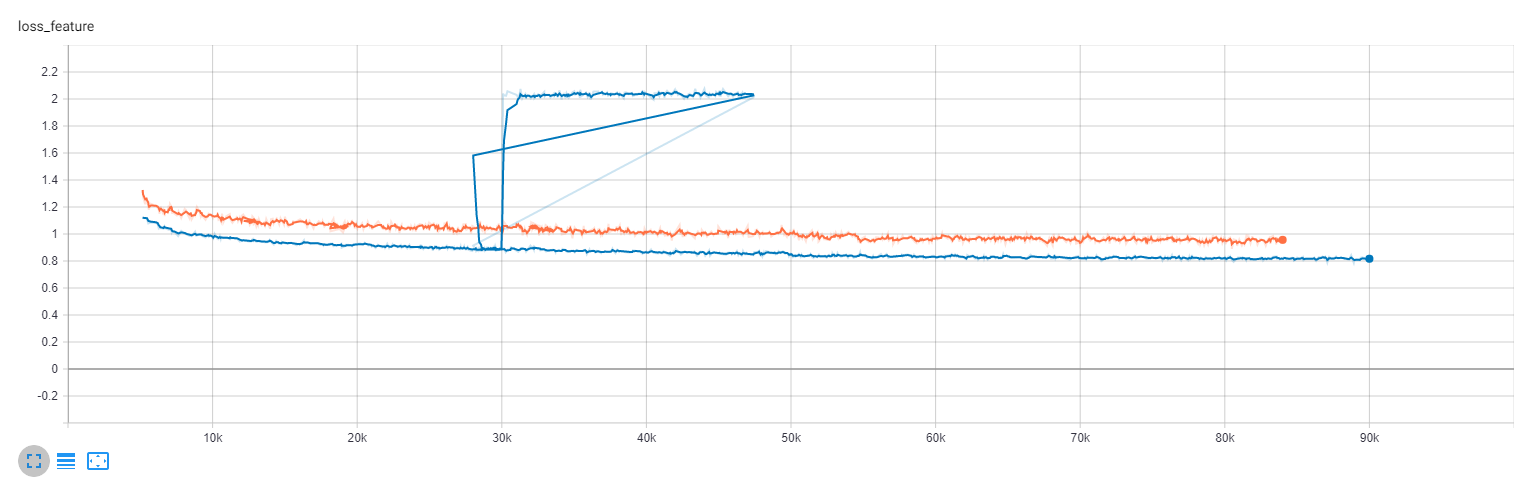
The plot above conveys my experience in general: a larger batch size does not just accelerate training, it permanently improves it. This difference is visible in the resulting images as well. Models trained on larger batch sizes exhibit less artifacts and more coherent fine image structures (e.g. eyes, hair, ears, fingers).
Here is an interesting anecdote from a recent experience I had with this: I am training an ESRGAN model and decided to move from training to 128×128 HQ images to 256×256. To accomplish this, I re-used the same model and added a layer to the discriminator. I decided to speed things up by reducing the batch size by a factor of 2. After nearly a week of training and many tens of thousands of iterations, the results were worse than what I had started with. After doubling the batch size, the model finally began to visually improve again.
Recommendations for larger batches
I’ve done some comparisons between the same model with different batch sizes. The performance improvement that comes with increasing batch size is nearly linear between batch-size=[16,128]. I have not experimented heavily past 128 due to my own computational budget limitations. Any model I am serious about these days gets a batch size of 128, though.
Accommodating Large Batches
As mentioned earlier, the authors of SR papers have good reason to recommend smaller batch sizes: the RRDB network proposed in ESRGAN consumes about 10GB of VRAM with a batch size of 16!
As I’ve worked on more SR topics, I’ve come up with several workarounds that can help you scale your batch sizes up.
- Gradient Accumulation – You can easily synthesize arbitrarily large batch sizes using a technique called gradient accumulation. This simply involves repeatedly summing the gradients from multiple backwards passes into your parameters before performing an optimizer step. This can affect models that use batch statistics, but shouldn’t matter for SRGAN models because they shouldn’t be using batch normalization. Gradient accumulation is controlled in DLAS using the
mega_batch_factorconfiguration parameter. - Gradient Checkpointing – This is an unfortunately named and underutilized feature of pytorch that allows you to prune out most of the intermediate tensors your model produces from GPU memory. This comes at the cost of having to re-compute these intermediate tensors in the backwards pass. Trust me: this is much faster than you think it is. The performance penalty of gradient checkpointing is often negligible simply because it allows you to fully utilize your GPU where you would otherwise only be partially using it. Gradient checkpointing is enabled in DLAS using the
checkpointing_enabledconfiguration parameter. - Mixed Precision – This is fairly old hat by now, but training in FP16 or in mixed precision mode will result in far lower memory usage. It can be somewhat of a pain, though, as evidenced above. Torch has recently made this a first-class feature.
(By the way, all of these are implemented in DLAS – my generative network trainer. Check that out if you are interested in trying these out without spending many hours tweaking knobs.)