
About a month ago, I decided to take the plunge into learning how to fine tune a language generation model. One use-case of language generation that I found particularly compelling was abstractive document summarization. A lot of the papers currently available that deal with abstractive summarization and transformers work by truncating the input text to the maximum sequence length of the model. In the post-transformer XL world, I thought it’d be neat to fix that limitation.
XLNet and TransformerXL are the two recurrent language models currently available in the Transformers NLP library. “Recurrent” in this context means that they were designed to model extremely long sequences by breaking those sequences into chunks and processing them one at a time. The chunks are then tied together via a “memory” that is recursively passed between from forward pass to the next.
XLNet is particularly interesting for language generation because it is pre-trained in a regressive manner similar to the GPT family of models. This holds the promise for more coherent text output than what you would typically find with MLM models like Transformer XL.
With all this in mind, I decided to try to fine-tune a model that could do abstractive summarization over an arbitrarily long corpus. I’ve been working on cracking this egg for about a month now, and have seen some success. In this post, I’m going to show you what I did. Along the way, you’ll learn about how XLNet works from a technical perspective and how you can use it for your NLP tasks.
I believe what is covered here could be used for just about any generative task that you have supervised data for. More importantly – you don’t even need to have much of that data. In my tests, the model converges after ~10,000 samples.
Who’s This Guide For?
I’m going to try my best not to go too far into the weeds in this post. I expect that you have a fairly strong knowledge of Python and PyTorch. You should generally know how language models work as well. This includes reading up on tokenizers, word embeddings, transformers, BERT. I will go into a bit more detail about segment recurrence and XLNet’s flavor of autogressive modeling, but you should still probably peruse the Transformer XL and XLNet papers if you want to get the most out of this post. You will also find the documentation for the Transformers library from Hugging Face useful, because a lot of this code is built on top of that library.
Worth noting: a data scientist I am not. This is not a paper, and I don’t mean for it to be one. It’s a practical guide on how to make XLNet produce real results for an interesting problem. I will not compare my work to prior art. Some unfounded conjecture will be made. I probably contort mathematics and terminology in awful, ugly ways. There are likely other problems. I apologize in advance for all this, and I welcome comments or pull requests.
The Plan
Before we dive into implementation details, let’s sketch out a rough design of what we’re going to build.
We have a pre-trained language model like XLNet, thanks to our friends at huggingface. We need a dataset. For the purposes of this article, that dataset is going to be a list of BBC news articles and their summaries generated via XSum. Click here to grab a zip file filled with XSum articles. We’re going to try to teach the model to generate a summary of an article given its text.
Each news article has text that spans thousands of tokens in length. Unfortunately, as you may have read – XLNet is a real monster of a model. A GPU with 16GB of VRAM can only handle sequence lengths of 256 tokens and a paltry batch size of 4 on the base XLNet model!
Fortunately, recurrence comes to the rescue. Even though we’re limited to 256 tokens, XLNet can model far longer sequences using a built-in memory mechanism. To exploit this, we are going to split up the text from our articles into chunks. Each chunk will be exactly 256 tokens.
To fine-tune the model, we will feed the chunks into the model one forward pass at a time. After each forward pass, we will collect the memory outputs from the model. We will then feed the next chunk into the model with the memory from the last pass. We will repeat this process until we get to the last chunk. This last chunk will have our “target” text appended to it, along with some masks that force the model to predict that target text during the forward pass. On this last pass, we will record the gradients and compute a loss against the target text. We will then perform gradient descent against the loss and (hopefully) end up with a better model of our objective.
Diving Into XLNet
Let’s talk about those “masks” I was talking about. XLNet has a ton of inputs for the forward pass. The really unique ones are perm_mask and target_mapping.
perm_mask is what separates XLNet from all the other models out there. Instead of corrupting the inputs with <mask> tokens like BERT, XLNet is trained by predicting each output given a limited input context. Put another way, every output token can only “pay attention” to a limited number of input tokens. Which tokens it can attend to are governed by the permutation mask. That mask is a square tensor of shape sequence_length x sequence_length. The first dimension selects an output token. The second dimension is set to 1 for tokens that cannot be used to predict that output token, and 0 for tokens that can be used.
If you’re familiar with the way the GPT model was trained, this is very similar. The difference is that XLNet is not constrained to predicting a sequence from left to right – it is trained to do so in any order. Interestingly, you can replicate sequential regressive predictions like the one GPT uses by just building a “stepped” permutation mask, which is just what we will end up using to train the model to predict our target text. I’ll dig into this in a bit more detail when we get to the code below, so don’t worry if you don’t completely get it yet.
target_mapping is another mask that allows you to tell the XLNet implementation how to map decoded tokens to labels so that a loss can be computed. For our purposes, this is going to be an eye tensor across the target text. This allows us to make the labels just the target text.
The transformers documentation is missing some details on how XLNet actually works. The model will internally activate one of two “attention modes” depending on the input parameters you feed it. The first mode activates if you fail to specify target_mapping or permutation_mask. In this mode, called “standard self-attention”, XLNet behaves similar to BERT and other MLMs. The second mode is “two-stream self attention”, which enables the permutation regressive language modeling that makes XLNet special. This was not clear to me when I started working on this project and I feel it is worth mentioning in case anyone else gets confused.
Alright, back to the plan. We’re going to use the permutation mask to force the model to predict the target sequence one word at a time – all in a single forward pass! To do this, the permutation mask needs to do something like this to the input:
SEQUENCE:
|<--------------- ARTICLE TEXT ------------------------> | <--------- SUMMARY -----------> |
A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got stuck in a tree<eos>
PERMUTATION MASK BY TARGET:
TARGET | <------------------------INPUT (*=permutation masked)------------------------------------> |
A A brown cat was stranded in a tree on Friday the 13th. <sep> * * * * * * * *
cat A brown cat was stranded in a tree on Friday the 13th. <sep> A * * * * * * *
got A brown cat was stranded in a tree on Friday the 13th. <sep> A cat * * * * * *
stuck A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got * * * * *
in A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got stuck * * * *
a A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got stuck in * * *
tree A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got stuck in a * *
<eos> A brown cat was stranded in a tree on Friday the 13th. <sep> A cat got stuck in a tree *
As you can see, every target word can only pay attention to target words before it. This is exactly how the model is going to work when we go to generate text – which should give us some great results!
Pre-processing the Dataset
In my recent work with language models, I’ve taken to processing my datasets in two stages.
In the first stage, I take raw data (that’d be a CSV/JSON/XML file) and extract out the relevant features (for example, the text and a classifier). I then feed the text through the appropriate tokenizer and save the results as a Pytorch pickle (e.g. with torch.save()).
In the second stage, the data is loaded into a Pytorch Dataset so that it can be batched, randomized, and served to the model.
There are a few reasons I separate these stages:
- It adds a layer of abstraction between the raw data and the logic that loads data into the model, which allows me to use multiple datasets with the same trainer programs.
- My train programs load much more quickly when they can operate off of the raw data produced from stage 1.
- I’ve been working in Windows a lot lately and Pytorch doesnt support dataloader workers in Windows. This means failing to separate the stages would significantly slow down training.
Stage 1
For the purposes of this post, I’m going to assume you are going to write your own stage 1 data processor. Here is an example of a stage 1 data processor that I wrote to process the XSum dataset. Th is is generally how that processor works:
tok = XLNetTokenizer.from_pretrained("xlnet-base-cased")
output = []
for data in datas:
text = data["text"]
text_enc = tok.encode(
text, add_special_tokens=False, max_length=None, pad_to_max_length=False
)
title = data["summary"]
title_enc = tok.encode(
title, add_special_tokens=False, max_length=None, pad_to_max_length=False
)
output.append({
"text": torch.tensor(text_enc, dtype=torch.long),
"target": torch.tensor(title_enc, dtype=torch.long),
})
torch.save(output, "out.pt")Stage 2
Stage 2 processing is where all the magic happens. We need a Pytorch Dataset class that can produce batches of “chunked” inputs. These chunks must then be sequentially fed into the model alongside the memory. After all the chunks in a batch are consumed, the memory is reset and a new batch of chunks is retrieved.
This is a challenging problem because the total number of chunks for any given text is not fixed. For example, one article might consist of 1000 tokens – or four 256-token chunks; another might be made up of 1500 tokens which would use six chunks. In order to do batched training, we need to randomly select batches of articles that use four chunks, then six chunks, etc.
To accomplish this, I’ve written the chunked text dataloader. This is an implementation of both Dataset and Dataloader that consume a stage-1 processed file and serves batches of chunked inputs with each input in the batch having the same number of chunks.
To enable the autoregressive language modeling of XLNet, this dataset also automatically appends the target text onto the end of input text and produces a permutation mask and target mapping for each chunk such that we achieve the masking I outlined in the example above.
I’m not going to dig into this code too much, since I feel I’ve done a good job documenting it. Check out the source code itself for more details. Just know when you see “ChunkedTextDataset” referenced below, this is where it is coming from.
Note that chunked_text_dataloader script can be executed. Doing so will produce a really neat view into the outputs it is producing, including a full permutation mask tree like the one I outlined above.
Fine-tuning XLNet
The actual training code looks very similar to the example code from the Transformers repo. There are a few differences, though. Lets walk through it.
We’ll start in the __main__ section. First, we process command line arguments, then we load the datasets:
# chunked_model_config is a dictionary initialized from command line arguments. Most fields
# are self-explanatory or can be inferred from the ChunkedTextDataset docs.
# Get the datasets
train_set = ChunkedTextDataset(
os.path.join(input_folder, "train.pt"),
tokenizer,
chunked_model_config["max_seq_len"],
chunked_model_config["predict_len"],
pad_left=True,
)
val_set = ChunkedTextDataset(
os.path.join(input_folder, "val.pt"),
tokenizer,
chunked_model_config["max_seq_len"],
chunked_model_config["predict_len"],
pad_left=True,
)
train_loader = train_set.get_dataloader(batch_size, num_workers=0)
val_loader = val_Next, we load up a XLNetConfig and XLNetModel from the Transformers pre-trained model database. This is where an important deviation takes place – you need to tell the model to output its mems by setting a “mem_len” in the config:
config = transformers.XLNetConfig.from_pretrained(
chunked_model_config["model_name"]
)
config.mem_len = chunked_model_config["mem_len"]
# config.num_labels = 1 # Un-comment this if you want
model = transformers.XLNetLMHeadModel.from_pretrained(
chunked_model_config["model_name"], Configuring the optimizer and scheduler are direct copy and pastes from the Transformers example with the exception of some provisions to enable what I call aggregate_batch_size. Since I can only train batches of size 3 at a time on my GPU, I wanted to combine several mini-batches together to get some of the benefits of larger batch size training.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p
for n, p in model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": 0,
},
{
"params": [
p
for n, p in model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer = transformers.AdamW(optimizer_grouped_parameters, lr=start_lr, eps=1e-8)
scheduler = transformers.get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=epochs * len(train_set) / aggregate_batch_size,
)Now we’re ready to run the training loop:
trainer = Trainer(
model,
chunked_model_config,
train_loader,
val_loader,
optimizer,
scheduler,
device,
fp16,
desired_batch_sz=aggregate_batch_size,
do_wandb=do_wandb,
)
model.zero_grad()
for _ in range(epochs):
trainer.loop()Let’s look at how the trainer classes loop() method works. This loop can do both validation and training loops, so you’ll see some split logic here. It starts off with some boilerplate:
def loop(self, _validate=False, _skip_batches=1):
# How many steps per logging event.
_logging_steps = 5
# How many steps between checkpoint save and validation.
_steps_till_save = 2000
_steps_till_validate = 2000
_dataloader = self.val_dataloader if _validate else self.train_dataloader
_epoch_iterator = tqdm(
_dataloader, desc="Val Iteration" if _validate else "Train Iteration")
# Total batches processed and number of times optimizer.step() has been called.
_steps, _optimizer_steps = 0, 0
# Aggregate losses.
_loss_sum, _logging_loss = 0, 0
_chunks = 0
self.clear_timers()
# This controls how many batches are required per optimizer step.
_batches_required_for_desired_sz = int(
self.desired_batch_sz / self.chunked_model_config["batch_size"]
)
if _validate:
torch.set_grad_enabled(False)
model.eval()
else:
self.model.train()Next we’ll start iterating through the batches. Let’s do a quick recap on what we’ll be getting inside of each batch. The batch returned from our dataloader is a dictionary. Each value in the dictionary (with the exception of “labels”) is a list of tensors. Each of those lists will have the same length. The lists are meant to be zipped together, and the aggregate collection of tensors you get by fetching one zipped entry is called a “chunk”. Here’s a psuedocode sketch of what a batch would look like if you printed it out:
{
"input_ids": [<batched_tensor1>, <batched_tensor2>, ..]
"attention_masks: [<batched_tensor1>, <batched_chunk2>, ..}
"permutation_masks": [..]
"target_mappings": [..] # Only appears if force_max_len_gen=True
"labels": <batched_tensor>
}Most of these values line up with inputs that the XLNet model is expecting. “labels” is only a single tensor because they are only fed into the model along with the last chunk. This is because only the last chunk contains the target text to be predicted.
The general algorithm is to loop over all of the chunks in the batch. The mems output from passing each chunk into model.forward() is saved and used as an input into the next forward() pass. The last chunk of every batch also feeds the labels in and computes a loss. We use this loss to backprop and update the model weights. There is some logic to support the aggregate_batch_size that we discussed earlier.
for _masked_input_ids, _attention_masks, _perm_mask, _target_mapping in zip(
_batch["input_ids"],
_batch["attention_masks"],
_batch["permutation_masks"],
_batch["target_mappings"],
):
_is_last_chunk = _chunk_counter == (_num_chunks - 1)
_chunk_counter += 1
# Forward
_inputs = {
"input_ids": _masked_input_ids.to(self.device),
"attention_mask": _attention_masks.to(self.device),
"perm_mask": _perm_mask.to(self.device),
"target_mapping": _target_mapping.to(self.device),
}
if _mems is not None:
_inputs["mems"] = _mems
# Only compute gradients on the last forward() per-chunkset.
if _is_last_chunk:
_inputs["labels"] = _labels.to(self.device)
_loss, _logits, _mems = self.model.forward(**_inputs)
else:
with torch.no_grad():
_logits, _mems = self.model.forward(**_inputs)
# Backwards
# Only compute backwards on the last chunk per chunkset.
if not _validate and _is_last_chunk:
_loss.backward()
backward_time = time.time() - __s
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1)
if not _validate and _step % _batches_required_for_desired_sz == 0:
# Update weights after all chunks have been processed at an interval to fulfill desired_batch_sz
self.optimizer.step()
self.scheduler.step()
self.model.zero_grad()
_optimizer_steps += 1
# Always accumulate loss across the last chunk, where it should be lowest. That's the goal of this model.
_loss_sum += _loss.item()
if not _validate and _steps % _logging_steps == 0:
_loss_scalar = (_loss_sum - _logging_loss) / _logging_steps
_logging_loss = _loss_sum
_logs = {
"avg_chunks": _chunks / _logging_steps,
"loss": _loss_scalar,
"learning_rate": self.scheduler.get_lr()[0],
"optimizer_steps": _optimizer_steps,
}
# Perform logging here.
# The train loop automatically runs a validation loop and saves checkpoints.
if not _validate:
if _steps % _steps_till_save == 0:
self.save_model("chkpt_%i" % (_steps))
if _steps % _steps_till_validate == 0:
self.loop(_validate=True, _skip_batches=10)In the next section, I’ll take a look at how the model turned out.
Results
I have been doing quite a few experiments with this set-up to see what kind of performance I can wring from it. There are some constants I’ve observed across all of these runs:
- The initial loss drops quite quickly early on (after ~20 steps) and follows a far more gradual trendline from there on out. Here is a pretty typical loss graph:
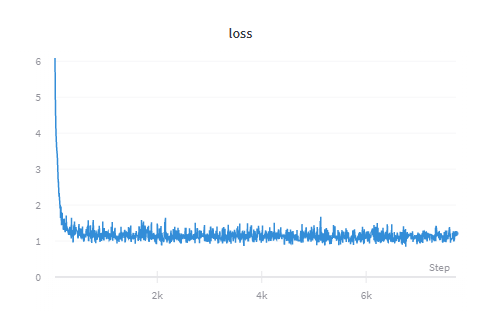
- Training for long periods of time seems to hurt the model rather than help it. The training and validation losses stay stagnant, but the generated text gradually loses its quality (quality in this case is just my own judgement, though I’m working on ways to make this more measurable). I believe what is happening is the model is losing the pre-trained language modeling capabilities in favor of being able to predict the idiosyncrasies of the target text.
- I developed a scheme for using a “aggregate batch size” where the gradients from individual batches are summed together to produce larger overall batches. This was necessary because my GPU could only do batches of 3 on the final model. Using this mechanism, I found that a “aggregate batch size” of 30-60 seemed to work best.
Text Generator
Due to the particular way this model was trained, you cannot use the stock Transformers Generator API to use it in test. This is because the model expects a sequence input with a fixed space for generation. The generation API only feeds the model sequences with a single <mask> token on the end. This model will almost always stick an <eos> token in that place because it thinks it has no room to actually create a summary. The other problem is that the existing generation API doesn’t accept chunked inputs and cannot be fed a mems to compensate.
To get around this, I hacked the Transformers library to work with my particular generation needs. Here is my fork. Here is the code that you can use to generate summaries.
From testing, I have found that sampling generally produces inferior generation results. I saw the results I present below with sampling turned off, num_beams=12 and repetition_penalty=5.
Ablation Testing
In this section, I want to answer two questions:
- Did my fine-training scheme improve model performance at all? Or is XLNet naturally good at producing text summaries?
- Does my chunking algorithm allow XLNet to improve performance by being able to recall past sequences, or is it primarily generating summaries based on the current sequence?
To test this, I will post demonstrative summaries from 5 different approaches:
- “human”: The first is the human generated summary that came with the XSum article.
- “base”: Summaries generated using a baseline XLNet model with no fine-tuning.
- “candidate”: The best fine-tuned XLNet model I produced during my testing.
- “no-mems”: The same fine-tuned model from (3) where mems are not recursively fed to the final chunk (e.g. not used).
- “corrupt-mems”: The same fine-tuned model from (3) where mems are generated from a single article text, and then applied to the same last chunk as the rest of these examples.
human: "The US, South Korea and Japan have said they will be united in their response to North Korea's claim to have successfully tested a hydrogen bomb."
base: "The North has denied any involvement in the test. However, South Korea and Japan have also expressed concern about Pyongyang's claims of a full thermonuclear explosion - \"a clear threat to international peace & security by its latest provocative act on Wednesday!\" Yonhap news agency reported that President Barack Obama had spoken separately with Mr Park over whether he supported further sanctions against his country after it carried out an"
candidate: "North Korea says it carried out a nuclear test on Wednesday."
no-mems: "The US and neighbouring countries are thought to be carrying out atmospheric sampling, hoping for leaked radioactive material which would give clues asto what kind of device was tested. South Korea is suspected North Korean testing a "boosted" atomic bomb that uses some fusion fuel to increase the yield on its nuclear reactors; officials have said Pyongyang has claimed a successful hydrogen bombs test whereas Seoul says it claims"
corrupt-mems: "Partick Thistle (Partick Heretle) won a free kick in the second half of their first-half win over Motherwell, but they were not able to convert an attempt from outside his own box. Danny Devine has been shown yellow cards for fouling Liam Lindsay on Saturday night when he was sent off after conceding two goals as part way through play at home against Dundee United and"
human: "Northampton hooker Dylan Hartley has been confirmed as England's captain for the Six Nations - two days after his six-week suspension for striking ended."
base: "The Australian was asked about his suitability for the role, Jones interrupted: \"I haven't actually told him. It is the continuity of this job that we can use as best I can to get our preparation right before the first game against France on 4 February at Twickenham in England and then we have a couple more days off! We are pleased with James Haskell back"
candidate: "England hooker Dylan Hartley has been given the all-clear to return as captain after being banned for two weeks."
no-mems: "England back row James Haskell has been given the all-clear to link up with France after recovering from a foot injury that kept him out for six months. Jones said people would \"have to wait and see if he will feature againstFrance in 11 days' time because of his lack thereof][ [lack] [[|]]\\{\u2022}</<> <nowiki*&#"
corrupt-mems: "Steven Lawless (Partick Thistle) has been shown the yellow card for a bad foul on Chris Cadden in his first match as part of Partick this season."
human: "Some of the damage caused by the recent floods could have been prevented if the correct water management techniques had been used, says a group of leading environmental and planning experts."
base: "In the letter to the Daily Telegraph, "The government will provide leadership and funding for a flood defence policy that is based on best practice developed over many years. It is essential if we are not addressing long-term problems of water management techniques such as stream alleviation streams in towns or cities like the Somerset Levels where flooding has been seen since December 2007 when it began with severe weather."
candidate: "The Prime Minister has called on the government to take action against flooding in England and Wales."
no-mems: "The government has announced its scheme to provide grants for homeowners in England hit by the floods and are spending \u00a32.4bn on flood management, protection from coastal erosion as part of our long-term planto improve resilience; we will look at the lessons that be learned to see where additional flooding can help\"Mr Cameron says he is looking forward too much Too MuchToo"
corrupt-mems: "Partick Thistle (Partick Heretle) won a free kick in the second half of their 2-1 win over Motherwell on Saturday."This testing was quite instructive. As expected, the baseline model tries to continue the article where it left off, as it doesn’t understand that we want a summary following the <sep> tag. We may be able to coax out better performance from this model by forcing it to predict text at the beginning of an article, but we would have no way to use memory in that case.
As for the mems ablation testing – wow! It is very clear that the model is using memory just by comparing the no-mems and candidate examples. The corrupt-mems examples shows just how much this model is leaning on memory, though. Some of the generated text completely ignores the context of the last chunk that it was given. It seems that the memory contributes more to most summaries than the preceding chunk text!
If you’d like to see some more sample outputs, skip a couple more sections below.
Work Needed
I suspect that there is one major shortcoming to my approach: I believe that the transformers library does not properly apply relative positional encodings to sequences recursively fed into it. What this effectively means is that the model doesn’t have context on where in a sequence of text the “stuff” it holds in its memory came from. Once you’ve processed two chunks into memory, they will likely be “jumbled” up. Fortunately for the purposes of document summarization, sequence ordering actually doesn’t matter all that much. However, this would be something that would be nice to fix for other use cases.
I also suspect that my data could be better cleaned. I remove some useless, repetitive text in my preprocessor but I know that some articles, for instance, are filled with gibberish and should be removed.
I would love to see how this model performs on xlnet-large-cased, which has more than 3x the parameters. I just don’t have the hardware on hand to do so.
Honestly, at this point, I’ve convinced myself that this type of pre-training is not the way forward for a truly game-changing text abstraction engine. The problem is that during training, I am forcing the model to predict my summarization examples, rather than produce good summarization models in general.
Think back to school – imagine if you were graded only by your ability to produce an exact copy of a “golden” book report. I suspect you wouldn’t learn much about expressing yourself.
I think the way forward is to have the model produce a summary and then get graded on it. I’m going to pursue that pursue rather than fine tuning this further. Stay tuned..
Alternatives Considered
This project has been through many iterations, a few of which are worth mentioning.
Before I understood that target_mapping was mandatory to get permutation modeling to work in XLNet, I tried an alternative scheme to pre-train the model. Instead of using the permutation_mask to force the model to predict all target tokens, I went with a variant of masked language modeling.
In this scheme, I pre-pended to target text onto each chunk and had the dataset mask out a high percentage of the target tokens (50% seemed to be a good settling point). Prepended text worked particularly well because it forced the model to predict where the target text ended and the article text began – and these models were actually quite good at producing proper length summaries. They also had very low losses – so they were quite good at the modeling task at hand. Unfortunately, their generation quality was fairly low. The summaries they produced sometimes looked like a summary, but were generally incoherent.
The logic behind prepending the target to every chunk was that it allowed me to compute a loss on every chunk and therefore perform optimizations on the model as often. One thing I worry about with my current permutation solution is that he model is not really learning how to use the memory properly because there is no stage where it is both producing memory and having gradients computed. The memory is always just something that is “there”, but is not fine tuned. This earlier scheme had to perform predictions on every chunk, which intuitively forced the model to optimize its internal state on every chunk. I do not have solid metrics to back up whether or not this actually matters, this is all conjecture.
Trying it out
I’ve put together a test model and a sample dataset which you can use to test the model out for yourself. In this section, I’ll document how you can do that. I’ll also show you how you can train it yourself.
Caveat: XLNet is no joke. Running the generation script on a CPU will take 20 minutes to 1 hour per inference. Keep in mind that it is doing up to 100 forward() passes on a 110M parameter model every inference. Running on a GPU currently requires 11GB of RAM at a minimum, you can reduce this by reducing the number of beams in the generator and reducing the batch size (further) in the trainer.
Set-up
First, download the model and the XSum test data.
Next, you’ll want to set-up your Python environment to match mine. Chances are this works fine on the latest Pytorch, but here’s the details for reproducibility.
pip install torch===1.4.0 torchvision===0.5.0
git clone https://github.com/neonbjb/transformers.git
git clone https://github.com/neonbjb/NonIntNLP.git
cd transformers
pip install .
cd ../NonIntNLP
git reset --hard remotes/origin/xlnet_xsum_train
cd PythonUse your own data
I’ve provided some test data to work against. If you want to have the model summarize your own text, you’ll first need to do some pre-processing on that data. I’ve provided a simple script to do that in the NonIntNLP repo. First, you need to create a JSON file called “input.json” that looks like this:
[
{ "text": "article text here",
"summary": "article summary here" },
{ "text": "article2 text here",
"summary": "article2 summary here" },
...etc...
]To preprocess this JSON file, run:
python processors/process_basic_json_for_summarization.pyGenerate summaries
To run the generator against the pretrained model, you’ll need a pre-trained model like the one you downloaded above and a pre-processed data file (test.pt). Invoke the generator as follows:
python generate_with_transformers_chunked.py --model_dir=<extracted_model_dir> --data_file=<extracted or generated test.pt> --number_to_generate=1 --device=cudaTrain the model
To train the model, you’ll first need some training data. You can download my XSum raw data and run it through processors/process_xsum.py. You’ll need to modify the code a bit for your system and file paths. I’ll leave that up to you to figure out. Once run, you’ll get three files: “train.pt”, “val.pt”, “test.pt”. To train a baseline Transformers model against these files, run the following command:
python train_xlnet_lang_modeler_pytorch.py --input_folder=<folder where val.pt and train.pt are stored> --epochs=1 --output_dir=<directory to save checkpoints> --seq_sz=256 --max_predict_sz=80 --batch_sz=3 --aggregate_batch_sz=36 --start_lr=5e-6 --device=cudaSome tips:
seq_szandbatch_szare what you want to modulate if you get a CUDA OOM error. I doubt you will be able to train on a GPU with less than 8GB of RAM.- XLNet has a
seq_szlimit of 512. Above this it should still work, but I believe the transformers library will automatically start using input recursion, which may reduce performance. I can’t test this because my GPU cannot handle it. Practically speaking, the model does fine atseq_sz=256. - This script does not currently support multi-GPU training, but it should be easy to implement.
start_lrshould be scaled alongsideaggregate_batch_sz.
More Sample Outputs
I ran the best combination of model and generator configuration options against 50 news articles from the XSum test set I generated and posted the results on Github here. I’ll spend this section discussing some of the results.
To start with, I think a good number of these generated summaries are pretty incredible! I’m going to focus on the negatives below, but I’d say the majority of the generated text looks and sounds like a summary, and many times gives the actual summary a run for it’s money.
This particular model has a penchant for producing short, succinct summaries. As a result, it often loses some important details that you would normally expect to see in a summary. For example:
Generated summary: “Former Chancellor George Osborne has been appointed as the new editor of The Sunday Times.”
Actual summary: “The rules on MPs taking second jobs are to be discussed by a parliamentary committee on Thursday.”
This article was mostly about the controversy surrounding Osborne’s appointment, not the appointment itself.
Like many automated text summarizers, this one sometimes struggles to get facts right. Here are a couple of pretty egregious examples:
Generated summary: “Scotland’s unemployment rate has fallen by more than half in the last three months, according to figures released today.”
Actual summary: “Unemployment in Scotland rose by 16,000 between November and January to stand at 171,000, according to official figures.”
Generated summary: “A man killed by a taxi driver in Glasgow has pleaded guilty to manslaughter.”Actual summary: “A lorry driver has admitted causing the death of a student after he drove through a red light and crashed into a taxi in Glasgow.”
The model occasionally has a penchant for run-on summaries which quickly lose their point. I can’t figure out what triggers this to happen. Here’s an example:
Generated summary: “Dublin Airport has apologised to customers for any inconvenience caused by a ground incident in which two aircraft clipped each other on the taxiway at its airport. Ryanair have said they were bused and boarded three replacement flights from Edinburgh FR812 & Zadar as passengers prepared their departures this morning, according to an Irish airline statement issued late Wednesday evening online via Twitter!”
Finally, the model occasionally will extract some information from an article, but totally miss the intended point. Here is an example:
Generated summary: “Women in the UK are being judged more than men, according to a new study.”
Actual summary: “Reverend Libby Lane has become the first female bishop.”
I’ll leave you off with an amusing example encountered in the test set. An article which is apparently filled with gibberish is fed into the model, and it responds with gibberish. 🙂
Generated summary: “Fe’i y datganiad wedi pry-droed a Mr Deguara difrifol car Vauxhall Caerdyd, ong mewn pa de la fru dux van Gael. Y fe cafwy Daddy Pesticcio no fos to go for his daughter Sophie Taylor as she was pregnant with her son Michael Wheeler at the”
Actual summary: “Mae menyw yn wynebu carchar wedi iddi achosi marwolaeth cyn-gariad ei chymar wrth ei rasio ar hyd strydoedd Caerdydd.”
Copywrite and Attribution
This code is under a creative commons license – do with it what you like. I only ask that if you do use this code or post in a public project or paper, that I you reference my name (James Betker) and this work.
How is Transformer XL a masked language model?
You’re right to call this out. When I said “Transformer XL” here I was referring to the huggingface language model using that name, which is (to my knowledge) trained via MLM. Transformer XL itself is not only a language model, though.