Overview
TorToiSe is a text-to-speech (TTS) program which can mimic voices given 2-4 examples. It is composed of five separately-trained neural networks that are pipelined together to produce the final output. This document will first go into details about each of the five models that make up Tortoise, and will wrap up with a system-level description of how they interoperate.
The Autoregressive Decoder
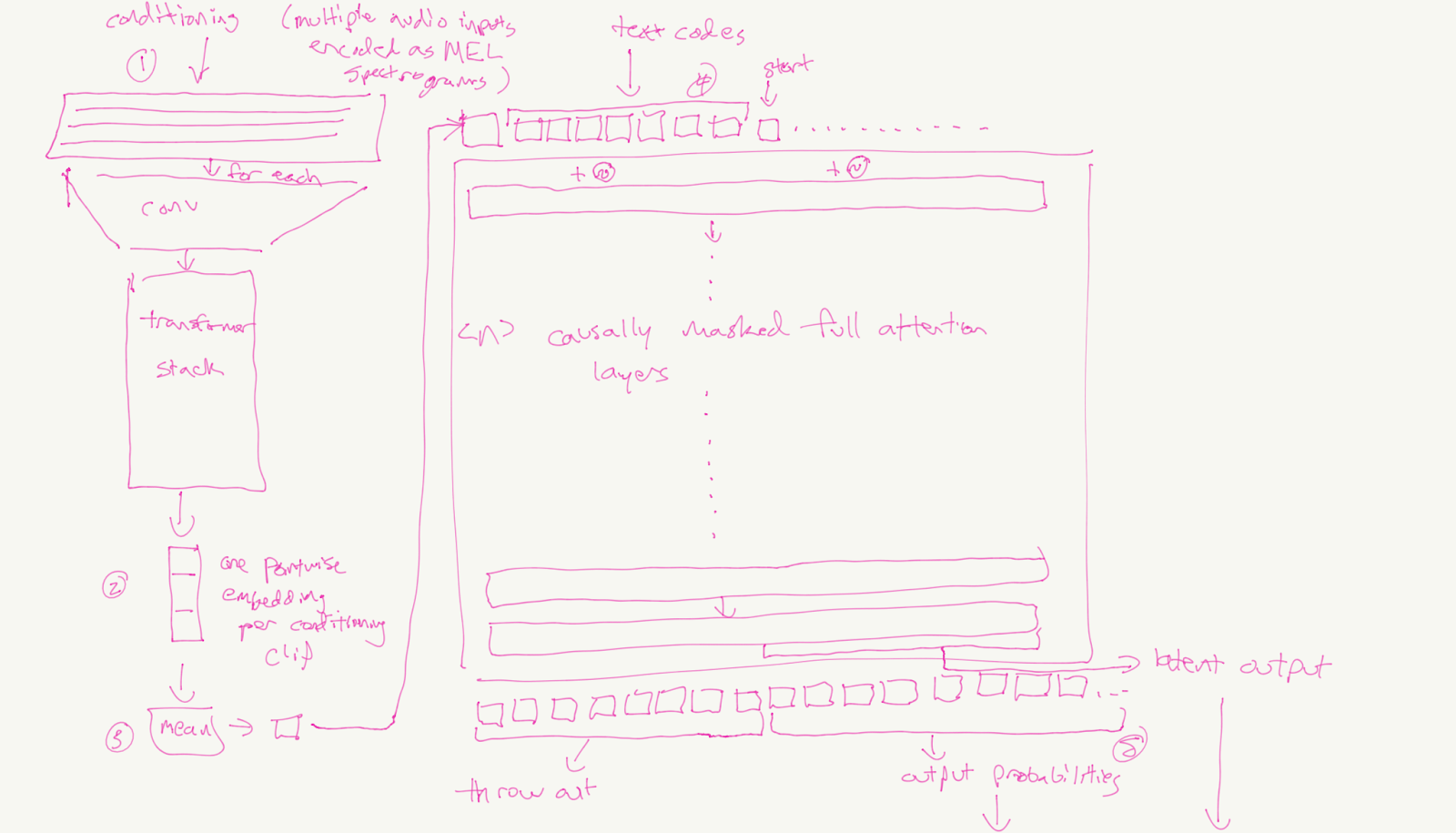
Reference Clips
A list of reference clips are also provided to the model. The model uses these clips to figure out how to properly mimic the voice, intonation, prosody, etc of the speech it is expected to produce. In code and the diagrams, the reference clips are referred to as “conditioning” inputs.
The reference clips are processed by a small model architecture reminiscent of ViT: A stack of reducing convolutions followed by a stack of full-attention transformers. At the head, we take the mean of all the elements in the sequence and return the result. We again take the mean of all of the reference clip latents produced in this way to produce a single reference latent, which is referred to as the “conditioning latent” in code.
Speech and Text Inputs
The autoregressive decoder is primarily responsible for translating between text to speech. To keep the problem tractable, speech audio sampled at 22kHz is first downsampled 1024x by first encoding it as a MEL spectrogram (a 256x compression) and then reducing it a further 4x using a VQVAE specifically trained on MEL spectrograms.
When compressed 1024x, the resulting speech audio has about 2x the spatial dimensions of the corresponding text. This is an entirely tractable problem for a flat transformer like the ones used in NLP.
Text is converted to tokens using a custom 256-token BPE lexicon which was trained on the text side of the speech dataset used. Speech is converted to 8192 tokens by the VQVAE mentioned above.
The Model
For the actual model, I experimented with multiple transformer architectures. The most compelling option was the standard encoder-decoder architecture. However, I ran into convergence problems as I scaled the depth of the decoder or the hidden size. For this reason, I opted to build a decoder-only architecture like is done with DALLE. Like DALLE, I used a GPT-2 model from the Huggingface Transformers library with a few minor modifications to support multiple modalities.
By using GPT-2, I was able to perform all of the computation within a single stack of transformer layers. As has been exhibited by OpenAI’s research, these types of models are trivial to scale and work well even in multi-modal situations. The final GPT architecture I settled on is composed of 30 layers, each with 16 attention heads and a hidden dimensionality of 1024. This comes out to 420M parameters total. As a point of comparison, GPT-2 is 1.5B parameters, DALLE is 12B and GPT-3 is 175B.
Unlike DALLE, I opted for full attention in all layers.
I trained a few toy models before committing to the full-size version I am distributing with Tortoise. Smaller models were successful but their multi-voice capabilities were poor. I strongly believe that this model would be an excellent candidate for scaling up. It clearly underfits the data, converging in under 3 epochs with no appreciable performance difference between train and validation datasets.
Composing the Inputs
Once both text and speech are tokenized and the conditioning latent has been computed, each of the text and speech sequences are padded with their own START and STOP tokens then fed through separate embeddings. We then build the inputs to the GPT-2 transformer by concatenating the three inputs as follows: [conditioning_point_latent, text_embeddings, voice_embeddings].
The resulting model is a next-token-prediction model with a twist: it can predict both text and speech tokens; the latter which is predicted by first giving the model some text tokens and a START voice token.
Issues
This model contains a probabilistic understanding of how text and speech relate to one another given a contextual voice. However, if you simply attempt to decode the highly compressed speech representations it outputs, it is nearly unintelligible. This is because the compression ratio at which it operates on the speech data means that a large amount of information about the audio signal has been lost.
The other issue with this model is that decoding it is ”challenging”. Performing beam search or greedy decoding will, more often than not, result in audio that sounds like a long stretched out “uhhhhhhhhhh” or just simply silence. This is a well-known issue with autoregressive decoding.
The solutions to both of the above problems are found in the other models that compose Tortoise. Let’s move on.
CLVP
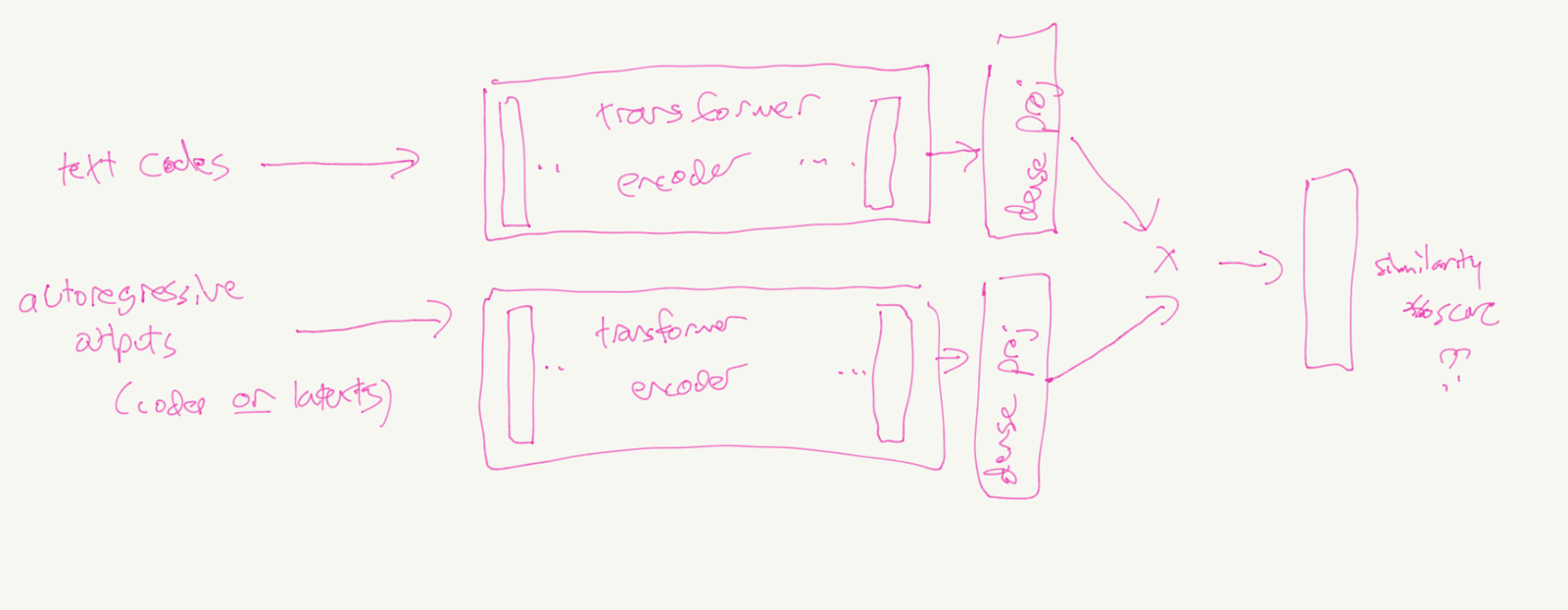
The Contrastive Language-Voice Pretraining (CLVP) model was built to solve the decoding challenges described above. In solving this, I used a technique similar to what is done with DALLE: nucleus sampling is used to generate a large number of candidates from the autoregressive decoder, then the CLVP model is used to select the most likely pairing of text and voice from those candidates.
In practice, this procedure works very well with the obvious downside being that you must first compute many candidates from the autoregressive model (an already expensive proposition by itself).
The Model
CLVP is very similar to the CLIP architecture it is based on, except that instead of images as the second modality, CLVP consumes the tokenized outputs of the autoregressive decoder (which are nominally highly-compressed audio clips). Tokenized inputs were used rather than raw audio or spectrograms because (as you will see), decoding these tokens to something resembling audio data is computationally expensive. CLVP seems to operate very well in the token-space, anyways.
Both the text and audio encoders of CLVP consist of a stack of 12 full attention transformer layers. The hidden dimension size is 512 with 8 attention heads. The model clocks in at 67M parameters.
CVVP
CVVP stands for “contrastive voice-voice pretraining”. This is a contrastive model that has learned to pair a clip of someone speaking something with the tokenized outputs of the autoressive decoder produced when fed the same person saying something else. Its purpose is to steer the autoregressive decoder towards outputs that are similar in vocal qualities to the reference clip provided.
CVVP is nearly identical to CLVP except it trades text for an audio clip.
CVVP’s contribution to Tortoise is minor. It could be entirely ommitted and you would still be left with a very good TTS program. I do not have a way to quantify its contribution to Tortoise, but I have subjectively been able to tell outputs that were generated with CVVP in the picture versus those that were generated without CVVP.
The Diffusion Decoder

The remaining problem that we need to tackle is decoding the highly compressed speech representations that the autoregressive decoder outputs back into actual waveforms that can be played on computer speakers. This is, at its core, a super-resolution problem. Diffusion models are the kings of super-resolution (well.. they are the kings of all generative models..) – so I naturally turned to them to perform this role.
The diffusion decoder takes the outputs of the autoregressive transformer and the reference clips and uses the two to build an actual MEL spectrogram.
The Model
The autoregressive outputs are first pre-processed by a stack of 4 full-attention blocks and an additional 3 combination full-attention/resnet blocks with timestep infusion. I call the outputs of this module the “codes”.
The reference clips are pre-processed into a point-latent with a ViT-style transformer stack, similar to the way the reference clips are pre-processed in the autoregressive decoder, described above. The output of this module is called the “conditioning latent”.
The conditioning latent is used to scale and shift the mean and variance of the codes latents. These mutated codes are then concatenated on to the input of the diffusion decoder before progressing through the main transformer stack described above.
Most diffusion models in literature are U-nets with full attention at the bottom layers. Since this diffusion decoder operates solely on MEL spectrogram data, which is fairly compressed, I was able to use a simpler architecture. The diffusion decoder is composed of a flat stack of 10 alternating full-attention layers and residual conv blocks. The hidden dimensionality is 1024 with 16 attention heads. This model clocks in at 292M parameters.
As is done in literature, the diffusion timestep signal is fed into the network and is used to modulate the mean and variance of the residual block outputs.
The Vocoder
With the architecture described above, we have a model that can produce MEL spectrograms when given text and some reference speech data. The last step is to convert that MEL into audio.
Fortunately, this type of scheme is common in TTS systems, so a lot of research has been poured into this problem over the past few years. Open-source vocoders like Waveglow or Univnet offer spectacular performance in converting MELs to speech, even for voices that were not in the training dataset.
For this reason, I opted to use an off-the-shelf vocoder: univnet. This vocoder has comparable performance to waveglow but inference is faster and the model size is smaller.
One consequence of this decision is that I am forced to output audio at the sample rate that univnet expects: 24kHz. This differs from the rest of the Tortoise models, which operate at 22kHz. Similarly, I was forced to use MEL spectrograms derived from old NVIDIA tacotron code, rather than the Pytorch libraries when interfacing with univnet (the two produce slightly different spectrograms). If you look at the code and are confused as to why the two sample rates and MEL converters exist – this is why.
Why Use a Vocoder at All?
Diffusion models are perfectly capable of synthesizing raw waveform data, so why did I decide to use a vocoder?
I actually spent a lot of time and resources attempting to do exactly that – build a diffusion model that produced waveforms. What I discovered, is:
- Operating on high-dimensional data meant I needed to use the U-net architecture, which is considerably less performant then the flat architecture I ended up with.
- Operating on high-dimensional data meant that the diffusion U-net had to have a very small channel count at the top few layers, which caused severe performance degradation.
- Repeatedly performing convolutions across this high-dimensional space (as is necessary with diffusion models at inference time) is extremely computationally inefficient.
- Vocoders that are freely available are insanely good at what they do.
System Level Description
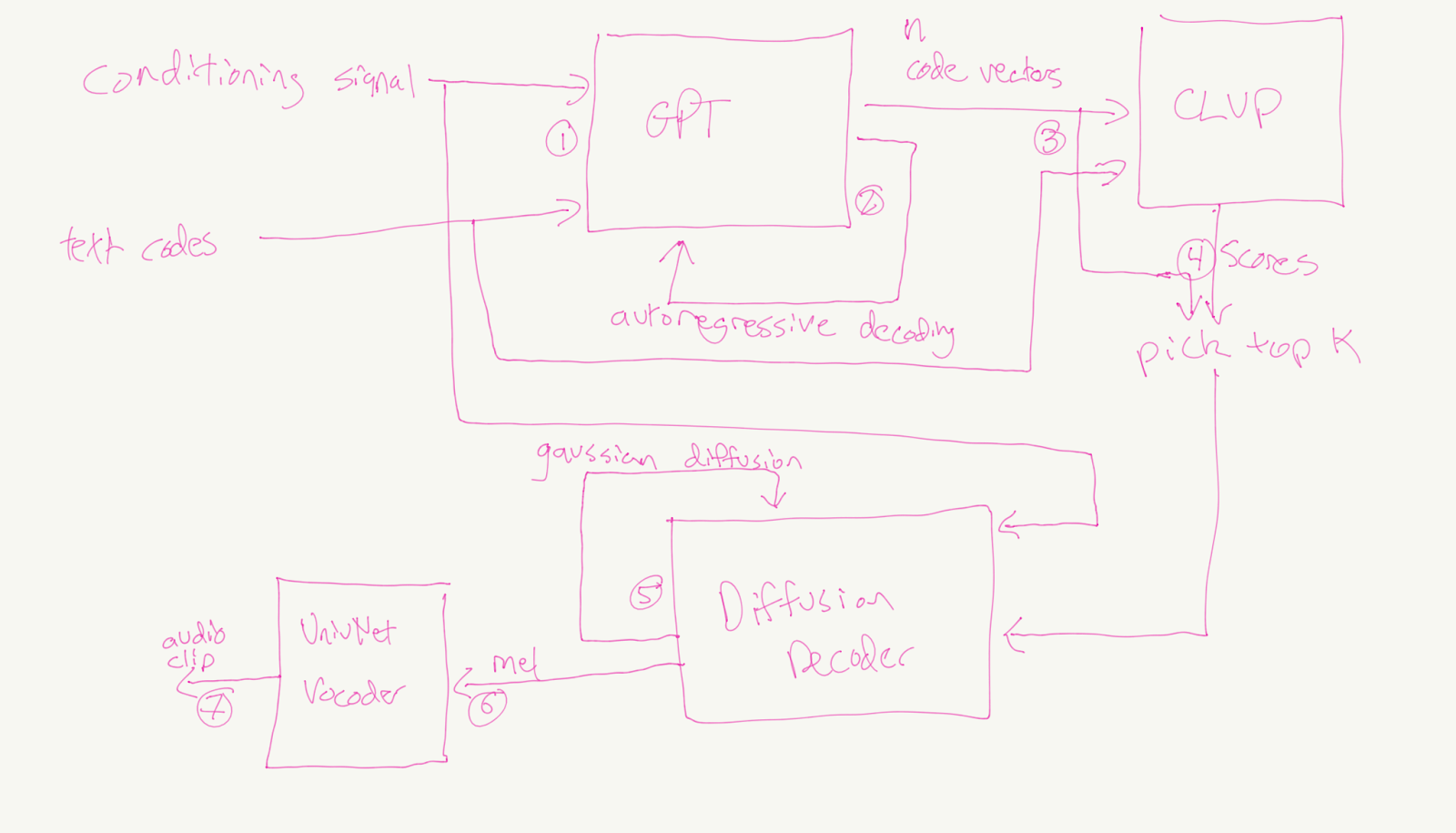
Now that we’ve described all the components of Tortoise, we can talk about how they work together to produce speech:
- The autoregressive decoder takes in text inputs and reference clips, and outputs latents and corresponding token codes that represents highly-compressed audio data.
- Nucleus sampling is used as the decoding strategy.
- This step is performed several times to produce many “candidate” latents.
- The CLVP and CVVP models pick the best candidate:
- The CLVP model produces a similarity score between the input text and each candidate code sequence.
- The CVVP model produces a similarity score between the reference clips and each candidate.
- The two similarity scores are joined together with a weighting provided by the Tortoise user. (CVVP and this composition is not pictured in the above diagram as it is a recent inclusion).
- The candidate with the highest total similarity is “chosen” to proceed to the next step.
- The diffusion decoder consumes the autoregressive latents and the reference clips to produce a MEL spectrogram representing some speech output.
- A univnet vocoder is used to transform the MEL spectrogram into actual waveform data.