I’ve updated the tortoise-tts repo with a script that automatically download model weights (thank to the HuggingFace Hub for hosting them!). I’ve also created a colab notebook if you want to try this out on Google hardware. Make sure you pick a GPU runtime. Sample outputs can be found in the results/ folder of the…
Author: jbetker
DALL E for TTS: TortoiseTTS
In an earlier post, I walked you through a project I’ve been working on, which I called “triforce” at the time. I’ve finished training a first pass on this collection of models and want to write about the results. Deploying this speech CLIP model on the outputs of my autoregressive speech token generator made all…
Batch speech transcription with ocotillo
As I mentioned in my previous blog post, I’m currently working on text-to-speech models. I’m taking the “scale-it-to-the-moon” approach, so I need a lot of data. Fortunately, speech data is pretty easy to come by. Audio books, podcasts, YouTube and large archives of speeches and presentations are available all over the internet. The problem is…
Triforce: A general recipe for kickass Generative Models
For the past two years, I’ve been tinkering around with generative models in my spare time. I think I’ve landed on an approach that produces by far the most compelling results available today, and which scales like big language models. I’d like to outline the approach here. First of all, I want to touch on…
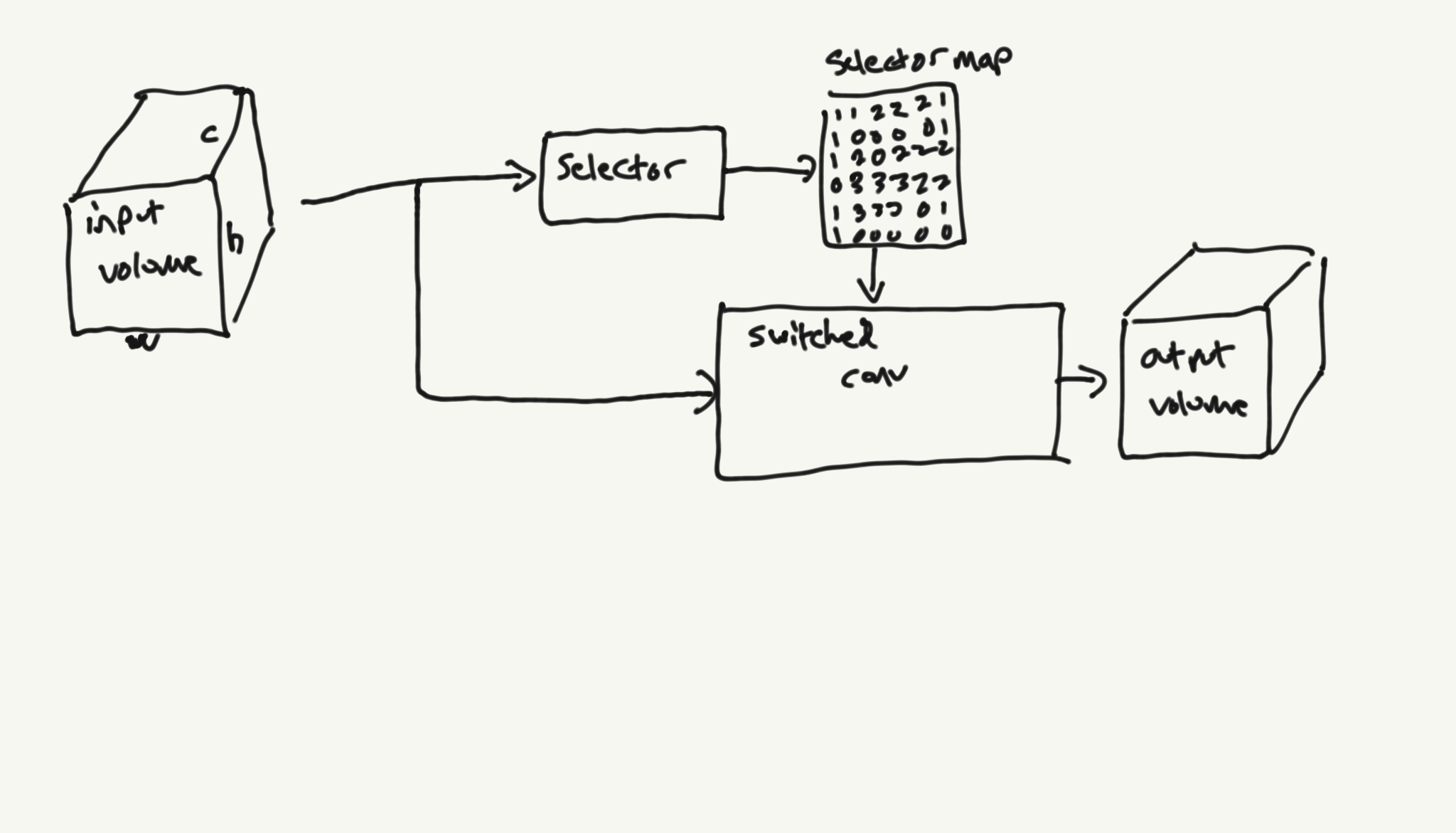
Switched Convolutions – Spatial MoE for Convolutions
Switched Convolutions – Spatial MoE for Convolutions Abstract I present switched convolutions: a method for scaling the parameter count of convolutions by learning a mapping across the spatial dimension that selects the convolutional kernel to be used at each location. I show how this method can be implemented in a way that has only a…
SRGANs and Batch Size
Batch size is one of the oldest hyper parameters in SGD, but it doesn’t get enough attention for super-resolution GANs. The problem starts with the fact that most SR algorithms are notorious GPU memory hogs. This is because they generally operate on high-dimensional images at high convolutional filter counts. To put this in context, the…
Training SRFlow in DLAS (and why you shouldn’t)
SRFlow is a really neat adaptation of normalizing flows for the purpose of image super-resolution. It is particularly compelling because it potentially trains SR networks with only a single negative-log-likelihood loss. Thanks to a reference implementation from the authors or the paper, I was able to bring a trainable SRFlow network into DLAS. I’ve had…
Translational Regularization for Image Super Resolution
Abstract Modern image super-resolution techniques generally use multiple losses when training. Many techniques use a GAN loss to aid in producing high-frequency details. This GAN loss comes at a cost of producing high-frequency artifacts and distortions on the source image. In this post, I propose a simple regularization method for reducing those artifacts in any…
Deep Learning Art School (DLAS)
At the beginning of this year, I started working on image super-resolution on a whim: could I update some old analog-TV quality videos I have archived away to look more like modern videos? This has turned out to be a rabbit hole far deeper than I could have imagined. It started out by learning about…
Accelerated Differentiable Image Warping in Pytorch
Computing optical flow is an important part of video understanding. There are many ways to train a model to compute this, but one of the more compelling methods is to: Feed a model an image pair Have it predict optical flow Apply that optical flow to the original image Compute a pixel-wise loss against the…